







Почему журналы сервера важны для SEO
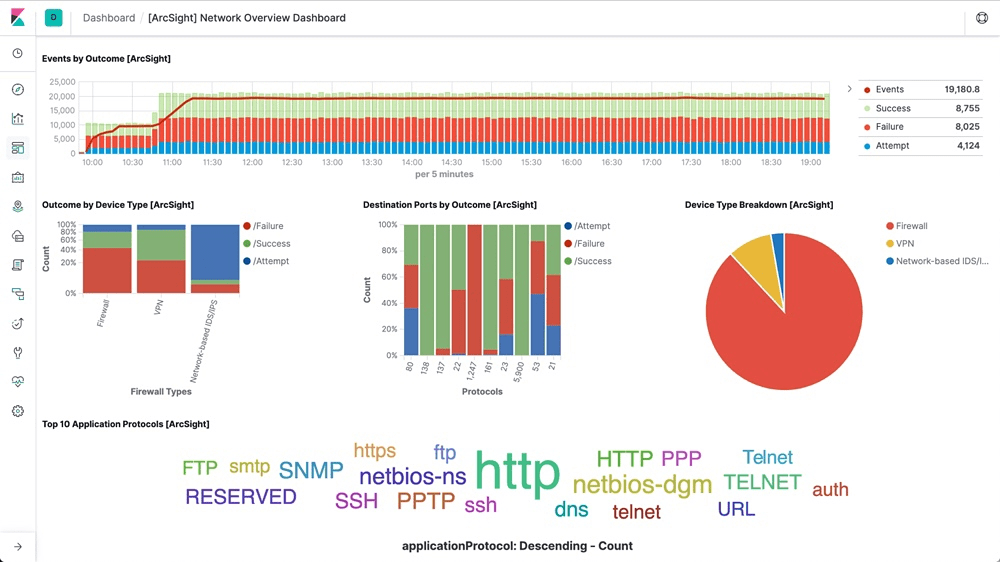
Анализ журнала сервера может предоставить непревзойденную информацию о приоритизации обхода контента, позволяя командам оптимизаторов оптимизировать управление бюджетом обхода для лучшего ранжирования.
Большинство операторов веб-сайтов не осознают важность журналов веб-сервера. Они не записывают и тем более не анализируют журналы сервера своего веб-сайта. Крупные бренды, в частности, не могут извлечь выгоду из анализа журналов серверов и безвозвратно теряют незарегистрированные данные журналов серверов.
Организации, которые решили использовать анализ журналов сервера в рамках своих текущих усилий по SEO, часто преуспевают в поиске Google. Если ваш веб-сайт состоит из 100 000 страниц или более и вы хотите узнать, как и почему журналы сервера открывают огромные возможности для роста, продолжайте читать.
Почему журналы сервера важны?
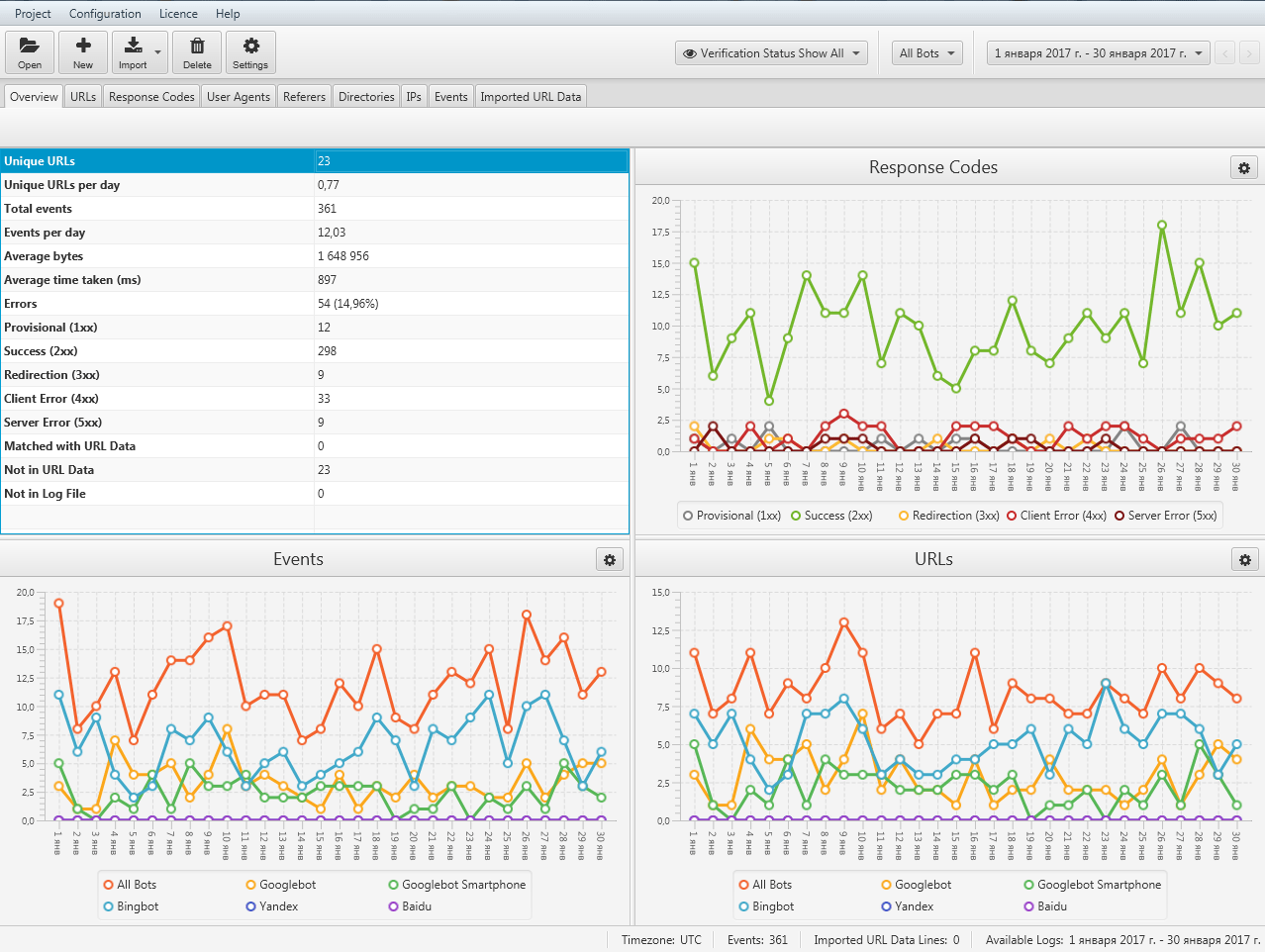
Каждый раз, когда бот запрашивает URL-адрес, размещенный на веб-сервере, автоматически создается запись журнала, отражающая обмен информацией в процессе. При охвате длительного периода времени журналы сервера становятся репрезентативными для истории полученных запросов и возвращенных ответов.
Информация, хранящаяся в файлах журнала сервера, обычно включает IP-адрес клиента, дату и время запроса, запрошенный URL-адрес страницы, код ответа HTTP, объем обслуживаемых байтов, а также пользовательский агент и реферер.
В то время как журналы сервера создаются при каждом запросе веб-страницы, включая запросы браузера пользователя, поисковая оптимизация фокусируется исключительно на использовании данных журнала бот-сервера. Это актуально в отношении юридических соображений, касающихся систем защиты данных, таких как GDPR/CCPA/DSGVO. Поскольку никакие пользовательские данные никогда не включаются в целях SEO, необработанный, анонимный анализ журнала веб-сервера остается свободным от других потенциально применимых правовых норм.
Стоит отметить, что в некоторой степени подобные выводы возможны на основе статистики сканирования Google Search Console. Однако эти образцы ограничены по объему и временному интервалу. В отличие от Google Search Console с данными, отражающими только последние несколько месяцев, исключительно лог-файлы сервера дают четкую общую картину с изложением долгосрочных тенденций SEO.
Ценные данные в журналах сервера
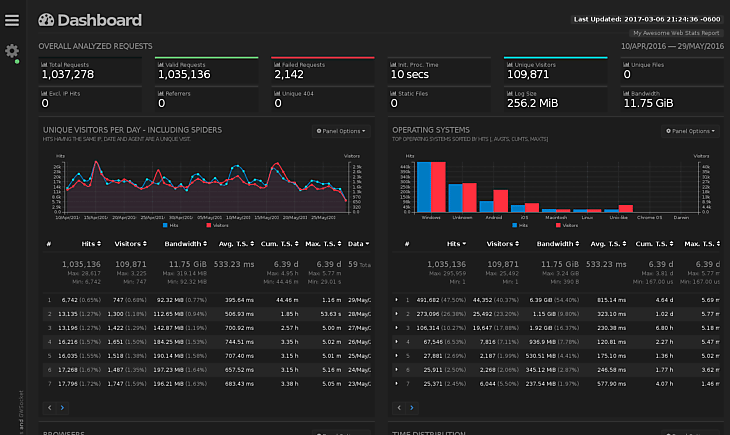
Каждый раз, когда бот запрашивает страницу, размещенную на сервере, создается экземпляр журнала, в котором записывается ряд точек данных, в том числе:
- IP-адрес запрашивающего клиента.
- Точное время запроса, часто основанное на внутренних часах сервера.
- URL-адрес, который был запрошен.
- Для запроса использовался HTTP.
- Возвращенный код состояния ответа (например, 200, 301, 404, 500 или другой).
- Строка пользовательского агента от запрашивающего объекта (например, имя бота поисковой системы, например Googlebot/2.1).
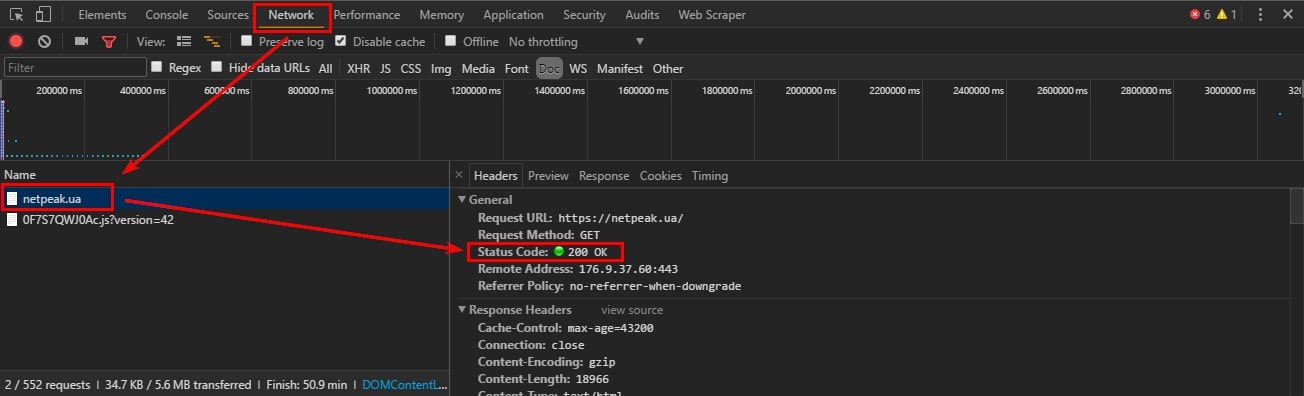
Типичный образец записи журнала сервера может выглядеть следующим образом:
150.174.193.196 - - [15/Dec/2021:11:25:14 +0100] "GET /index.html HTTP/1.0" 200 1050 "-" "Googlebot/2.1 (+http://www.google.com /bot.html)" "www.example.ai"
В этом примере:
- 150.174.193.196 — это IP-адрес запрашивающего объекта.
- [15/Dec/2021:11:25:14 +0100] — часовой пояс, а также время запроса.
- «GET /index.html HTTP/1.0» — используемый метод HTTP (GET), запрошенный файл (index.html) и используемая версия протокола HTTP.
- 200 — это возвращенный сервером код состояния HTTP.
- 1050 — размер ответа сервера в байтах.
- «Googlebot/2.1 (+http://www.google.com/bot.html)» — это пользовательский агент запрашивающей организации.
- «www.example.ai» — это URL-адрес ссылки.
Как использовать журналы сервера?
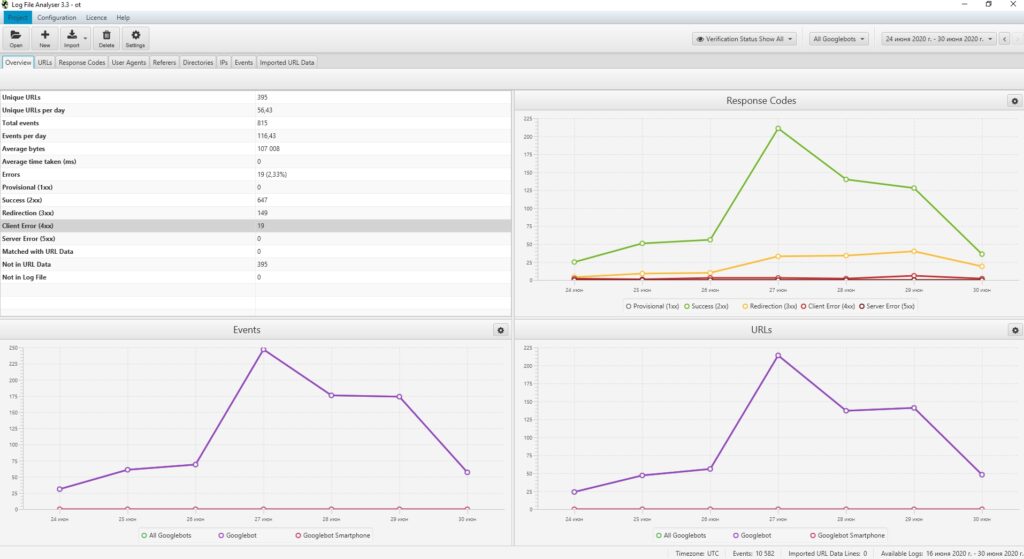
С точки зрения SEO, есть три основные причины, по которым журналы веб-сервера предоставляют беспрецедентную информацию:
- Помощь в отфильтровывании нежелательного трафика ботов, не имеющего значения для SEO, из желаемого трафика ботов поисковых систем, исходящего от законных ботов, таких как Googlebot, Bingbot или YandexBot.
Предоставление SEO-информации о приоритизации сканирования и, таким образом, предоставление SEO-команде возможности заблаговременно настраивать и настраивать управление своим краулинговым бюджетом. - Разрешение для мониторинга и предоставления послужного списка ответов сервера, отправленных поисковым системам.
- Поддельные боты поисковых систем могут доставлять неудобства, но они редко влияют на веб-сайты. Существует ряд специализированных поставщиков услуг, таких как Cloudflare и AWS Shield, которые могут помочь в управлении нежелательным трафиком ботов. В процессе анализа журналов веб-сервера поддельные боты поисковых систем, как правило, играют второстепенную роль.
Чтобы точно определить, какие части веб-сайта имеют приоритет, кроме основных поисковых систем, трафик ботов должен быть отфильтрован при выполнении анализа журнала. В зависимости от целевых рынков основное внимание может быть уделено ботам поисковых систем, таким как Google, Apple, Bing, Yandex или другим.
Особенно для веб-сайтов, где актуальность контента является ключевым фактором, частота повторного сканирования этих сайтов может критически повлиять на их полезность для пользователей. Другими словами, если изменения контента не будут улавливаться достаточно быстро, сигналы взаимодействия с пользователем и ранжирование в органическом поиске вряд ли полностью реализуют свой потенциал.
Хотя Google склонен сканировать всю доступную информацию и регулярно повторно сканировать уже известные шаблоны URL, его ресурсы сканирования не безграничны. Вот почему для крупных веб-сайтов, состоящих из сотен тысяч целевых страниц, циклы повторного сканирования зависят от алгоритмов распределения приоритетов сканирования Google.
Это распределение может быть положительно стимулировано надежными веб-сервисами с высокой скоростью отклика, оптимизированными специально для быстрой работы. Только эти шаги способствуют SEO. Однако только путем анализа полных журналов сервера, которые охватывают длительный период времени, можно определить степень совпадения между общим объемом всех доступных для сканирования целевых страниц и, как правило, меньшим количеством релевантных, оптимизированных и индексируемых целевых страниц SEO, представленных в Карта сайта и то, что Google регулярно отдает приоритет сканированию, индексированию и ранжированию.
Такой анализ логов как неотъемлемая часть технического SEO-аудита и единственный метод выявить степень растраты краулингового бюджета. И независимо от того, фильтрация для сканирования, заполнители или страницы с ограниченным содержанием, открытый промежуточный сервер или другие устаревшие части веб-сайта продолжают ухудшать сканирование и, в конечном итоге, ранжирование. При определенных обстоятельствах, таких как запланированная миграция, именно выводы, полученные в результате SEO-аудита, включая анализ журналов сервера, часто определяют успех или неудачу миграции.
Кроме того, анализ журнала предлагает для крупных веб-сайтов важную информацию о SEO. Это может дать ответ на вопрос, сколько времени нужно Google для повторного сканирования всего веб-сайта. Если этот ответ окажется слишком длинным — месяцы или дольше — могут потребоваться действия, чтобы убедиться, что индексируемые целевые страницы SEO просканированы. В противном случае существует большой риск того, что любые улучшения SEO на веб-сайте останутся незамеченными поисковыми системами в течение нескольких месяцев после выпуска, что, в свою очередь, является рецептом для низкого рейтинга.
Ответы сервера имеют решающее значение для хорошей видимости в поиске Google. Хотя Google Search Console предлагает важную информацию о последних ответах сервера, любые данные, которые Google Search Console предлагает операторам веб-сайтов, следует рассматривать как репрезентативную, но ограниченную выборку. Хотя это может быть полезно для выявления вопиющих проблем, с помощью анализа журнала сервера можно проанализировать и идентифицировать все ответы HTTP, включая любые количественно релевантные ответы, отличные от 200 OK, которые могут поставить под угрозу ранжирование. Возможные альтернативные ответы могут свидетельствовать о проблемах с производительностью (например, 503 Служба недоступна, запланированное время простоя), если они чрезмерны.
С чего начать?
Несмотря на потенциал, который может предложить анализ журнала сервера, большинство операторов веб-сайтов не используют представленные возможности. Журналы сервера либо вообще не записываются, либо регулярно перезаписываются, либо являются неполными. Подавляющее большинство веб-сайтов не хранят данные журнала сервера в течение какого-либо значимого периода времени. Это хорошая новость для всех операторов, желающих, в отличие от своих конкурентов, собирать и использовать файлы журналов сервера для поисковой оптимизации.
При планировании сбора данных журнала сервера стоит отметить, какие поля данных как минимум должны быть сохранены в файлах журнала сервера, чтобы данные можно было использовать. Ориентиром можно считать следующий список:
- удаленный IP-адрес запрашивающего объекта.
- строка пользовательского агента запрашивающего объекта.
- схема запроса (например, был ли HTTP-запрос для http или https или wss или что-то еще).
- имя хоста запроса (например, для какого субдомена или домена был HTTP-запрос).
- путь запроса, часто это путь к файлу на сервере в виде относительного URL.
- параметры запроса, которые могут быть частью пути запроса.
- время запроса, включая дату, время и часовой пояс.
- способ запроса.
- код статуса ответа http.
- сроки ответа.
Если путь запроса является относительным URL-адресом, поля, которыми часто пренебрегают в файлах журнала сервера, — это запись имени хоста и схемы запроса. Вот почему важно уточнить у своего ИТ-отдела, является ли путь запроса относительным URL-адресом, чтобы имя хоста и схема также записывались в файлы журнала сервера. Простым обходным решением является запись всего URL-адреса запроса в виде одного поля, которое включает схему, имя хоста, путь и параметры в одной строке.
При сборе файлов журнала сервера также важно включать журналы, происходящие из CDN и других сторонних служб, которые может использовать веб-сайт. Регулярно проверяйте в этих сторонних службах, как извлекать и сохранять файлы журналов.
Преодоление препятствий для анализа журнала сервера
Часто для противодействия острой необходимости сохранения данных журнала сервера выдвигаются два основных препятствия: стоимость и юридические проблемы. Хотя оба фактора в конечном итоге определяются индивидуальными обстоятельствами, такими как составление бюджета и юрисдикция, ни один из них не должен создавать серьезных препятствий.
Облачное хранилище может быть долгосрочным вариантом, а физическое аппаратное хранилище также, вероятно, ограничивает стоимость. При розничных ценах на жесткие диски емкостью примерно 20 ТБ ниже 600 долларов США стоимость оборудования незначительна. Учитывая, что цены на оборудование для хранения снижались в течение многих лет, в конечном итоге стоимость хранения вряд ли станет серьезной проблемой для записи журналов сервера.
Кроме того, будут расходы, связанные с программным обеспечением для анализа журналов или с поставщиком услуг SEO-аудита, оказывающим услугу. Хотя эти затраты должны быть учтены в бюджете, опять же, их легко оправдать в свете преимуществ, которые предлагает анализ журналов серверов.
Хотя эта статья предназначена для описания неотъемлемых преимуществ анализа журнала сервера для SEO, ее не следует рассматривать как юридическую рекомендацию. Такая юридическая консультация может быть предоставлена только квалифицированным адвокатом в контексте правовой базы и соответствующей юрисдикции. В этом контексте может применяться ряд законов и правил, таких как GDPR/CCPA/DSGVO. Конфиденциальность является серьезной проблемой, особенно при работе из ЕС. Однако для целей анализа журнала сервера для SEO любые данные о пользователях не имеют значения. Любые записи, которые не могут быть окончательно проверены на основе IP-адреса, следует игнорировать.
Что касается соображений конфиденциальности, любые данные журнала, которые не проходят проверку и не являются подтвержденным ботом поисковой системы, не должны использоваться, а вместо этого могут быть удалены или анонимизированы по истечении определенного периода времени на основе соответствующих юридических рекомендаций. Этот испытанный подход регулярно применяется некоторыми из крупнейших операторов веб-сайтов.
Когда начинать?

Основной остающийся вопрос заключается в том, когда начинать собирать данные журнала сервера. Ответ сейчас!
Данные журналов сервера можно применять осмысленно и давать действенные рекомендации только в том случае, если они доступны в достаточном объеме. Критическая масса полезности серверных журналов для SEO-аудита обычно колеблется от шести до тридцати шести месяцев, в зависимости от размера веб-сайта и его сигналов приоритета сканирования.
Важно отметить, что незаписанные журналы сервера нельзя получить на более позднем этапе. Скорее всего, любые усилия по хранению и сохранению серверных журналов, предпринятые сегодня, принесут плоды уже в следующем году. Следовательно, сбор данных журнала сервера должен начинаться как можно раньше и продолжаться непрерывно, пока веб-сайт работает и стремится хорошо работать в обычном поиске.
Источник: https://searchengineland.com/why-server-logs-matter-for-seo-378199
-
 NikeFIT
NikeFIT - 12.01.2022
- 2 991
- 2


Что такое клоакинг в SEO? Полный разбор что это

Продвижение интернет магазина: Как создать

Как улучшить EEAT и повысить авторитетность

Почему мой сайт не появляется в поисковых

Оптимизация изображений для сайта - Чек-лист и
12 советов по локальному SEO для малого бизнеса,
Я делюсь самыми интересными и полезными новостями из мира сео: Google, Яндекс.
Лучшие новости
Комментарии

ТОП-5 стран для регистрации IT-компании
Нет, у меня нет знакомых ИТ-шников которые переехали в Польшу, другие страны есть, что в статье иNikeFIT, 3 мая 2025 08:49
ТОП-5 стран для регистрации IT-компании
Интересная статья — тема прям актуальная, особенно сейчас, когда многие думают о переезде. ПроАлекс, 2 мая 2025 10:45
Что такое seo-текст: раскрываем все карты!
thank you very muchMichaelfip, 5 ноября 2023 18:15
Что такое клоакинг в SEO? Полный разбор что это такое cloaking и как клоачить
баловались мы таким, но даже в серой нише сейчас не актуально. блочится и пессимизируется сразу яшаАльмаматер, 8 августа 2023 09:05
Продвижение интернет магазина: Как создать успешную SEO-стратегию для интернет-магазина?
Сейчас актуальное это программное сео, когда ты по алгоритму расширяешь структуру сайта иАльмаматер, 8 августа 2023 09:04
Все комментарии..
Полный список последних комментариев
Крутите ПФ?
Теги
Страницы
Loading...
Нашли ошибку?
Вы можете сообщить об этом администрации.
Выделив текст нажмите CTRL+Enter